PaddlePaddle#
PaddlePaddle 是百度的一款深度学习框架。在开始之前,确保你已经在电脑上装好了 paddlepaddle。
Note
paddle 是核心代码,paddlex 是更上层的接口。 为了便于理解,可以将 paddle 理解为操作系统,而 paddlex 是运行在操作系统上的应用程序。 除了 paddlex,飞桨 PaddlePaddle 还为我们提供了更多更丰富的上层组件,如下图所示。
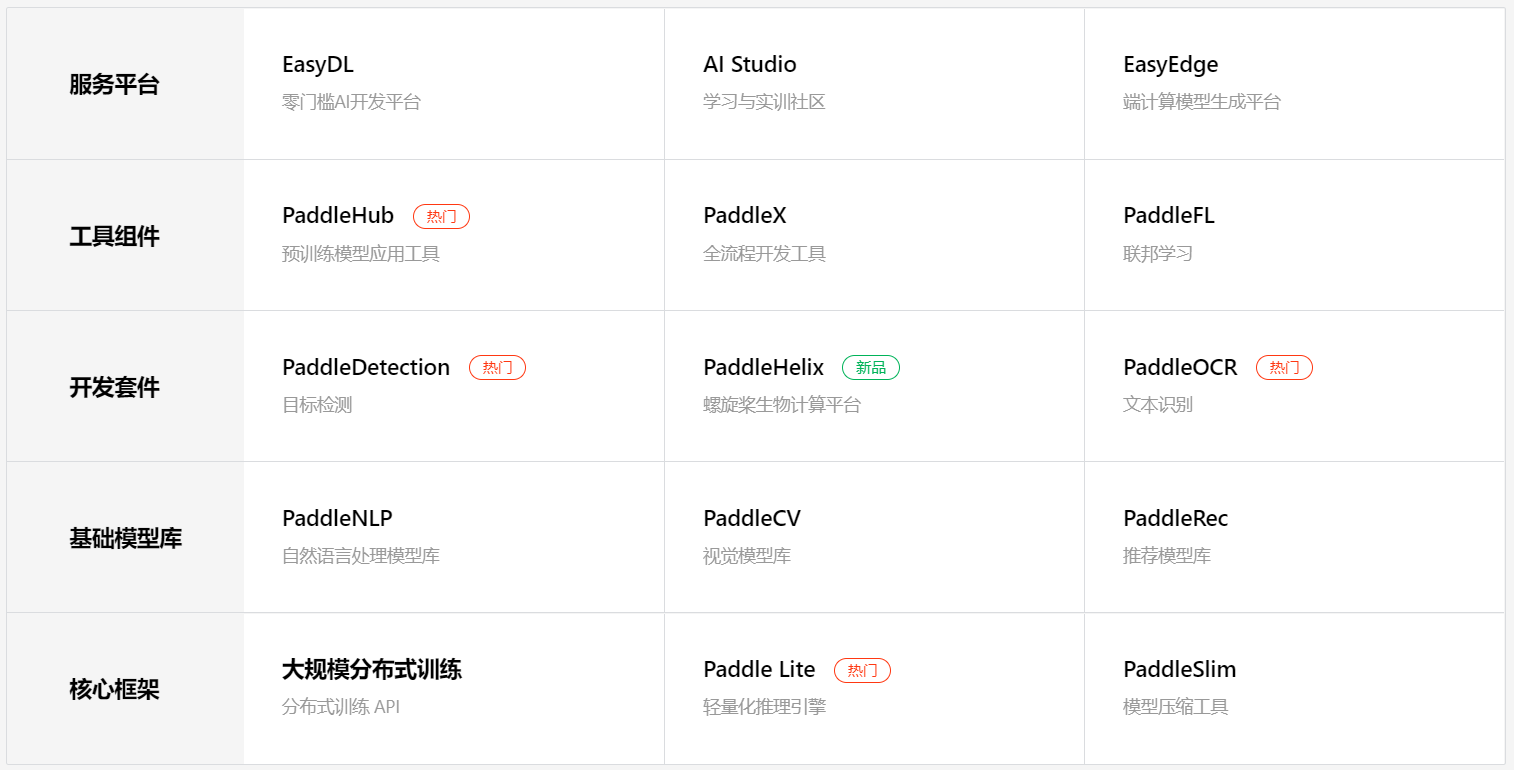
Fig. 18 PaddlePaddle 全家桶#
使用这些上层组件的前提是,你已经在电脑上装好了 paddlepaddle,因为他们需要使用 paddle 这个底层接口。
本文将记录如何使用 paddle,并不对上层工具做具体介绍。 使用 paddle 一般分为三个核心步骤:
定义 transforms 和 datasets;
定义模型(模型组网);
模型训练和预测(模型评估)。
下面以随机生成的数据为样本,测试流程的完整性。
定义 transforms 和 datasets#
import paddle
from paddle.io import Dataset
from paddle.vision.transforms import Compose, Resize
BATCH_SIZE = 64
BATCH_NUM = 20
IMAGE_SIZE = (28, 28)
CLASS_NUM = 10
# 定义自定义数据集
class MyDataset(Dataset):
# 实现构造函数
def __init__(self, num_samples):
super(MyDataset, self).__init__()
# 定义数据集大小
self.num_samples = num_samples
# 定义 transforms 方法,此处为调整图像大小
self.transform = Compose([Resize(size=32)])
# 指定 index 时如何获取数据
def __getitem__(self, index):
# 生成 IMAGE_SIZE 大小的随机数据
data = paddle.uniform(IMAGE_SIZE, dtype='float32')
# 使用 transforms 方法
data = self.transform(data.numpy())
label = paddle.randint(0, CLASS_NUM-1, dtype='int64')
# 返回单条数据(训练数据,对应的标签)
return data, label
# 返回数据集总数目
def __len__(self):
return self.num_samples
内置 datasets 和 transforms
视觉相关数据集:
['DatasetFolder', 'ImageFolder', 'MNIST', 'FashionMNIST',
'Flowers', 'Cifar10', 'Cifar100', 'VOC2012']
自然语言相关数据集:
['Conll05st', 'Imdb', 'Imikolov', 'Movielens', 'UCIHousing', 'WMT14', 'WMT16']
数据处理方法:
['BaseTransform', 'Compose', 'Resize',
'RandomResizedCrop', 'CenterCrop', 'RandomCrop',
'RandomHorizontalFlip', 'RandomVerticalFlip', 'RandomRotation',
'Transpose', 'Normalize',
'BrightnessTransform', 'SaturationTransform', 'ContrastTransform',
'HueTransform', 'ColorJitter', 'Pad', 'Grayscale',
'ToTensor', 'to_tensor', 'hflip', 'vflip', 'resize',
'pad', 'rotate', 'to_grayscale', 'crop', 'center_crop',
'adjust_brightness', 'adjust_contrast', 'adjust_hue', 'normalize']
定义模型(模型组网)#
飞桨提供了两种构建模型的方式:
Sequential组网:针对顺序的线性网络结构;SubClass组网:针对一些比较复杂的网络结构。
组网相关的 API 都在 paddle.nn 下。
Sequential 组网#
myModel = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
SubClass 组网#
class MyModel(paddle.nn.Layer):
def __init__(self):
super(MyModel, self).__init__()
# 对 Layer 进行声明
self.flatten = paddle.nn.Flatten(1, -1)
self.linear_1 = paddle.nn.Linear(1024, 512)
self.linear_2 = paddle.nn.Linear(512, 10)
self.relu = paddle.nn.ReLU()
self.dropout = paddle.nn.Dropout(0.2)
# 定义模型(前向计算)
def forward(self, inputs):
y = self.flatten(inputs)
y = self.linear_1(y)
y = self.relu(y)
y = self.dropout(y)
y = self.linear_2(y)
return y
内置模型
飞桨框架内置模型:
['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152',
'VGG', 'vgg11', 'vgg13', 'vgg16', 'vgg19',
'MobileNetV1', 'mobilenet_v1', 'MobileNetV2', 'mobilenet_v2',
'LeNet']
使用方法:
lenet = paddle.vision.models.LeNet()
paddle.summary(lenet, (64, 1, 28, 28)) # 查看网络结构
模型训练和预测#
飞桨提供了两种方式进行训练和预测:
先用
paddle.Model封装模型,再用高层 API:Model.fit(),Model.evaluate(),Model.predict();直接使用基础 API。
使用高层 API#
# 加载自定义数据集
custom_dataset = MyDataset(BATCH_SIZE * BATCH_NUM)
# 封装模型
myModel = MyModel()
model = paddle.Model(myModel)
# 为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(custom_dataset,
epochs=5,
batch_size=64,
verbose=1)
# 用 evaluate 在测试集上对模型进行验证
eval_result = model.evaluate(custom_dataset, verbose=1)
# 用 predict 在测试集上对模型进行测试
test_result = model.predict(custom_dataset)
使用基础 API#
模型训练#
# 加载自定义数据集
custom_dataset = MyDataset(BATCH_SIZE * BATCH_NUM)
train_loader = paddle.io.DataLoader(custom_dataset, batch_size=BATCH_SIZE, shuffle=True)
model = MyModel()
model.train()
# 设置优化器,损失函数和精度计算方式
optim = paddle.optimizer.Adam(parameters=model.parameters())
loss_fn = paddle.nn.CrossEntropyLoss()
epochs = 5
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0] # 训练数据
y_data = data[1] # 标签
# 调用前向计算
predicts = model(x_data)
# 计算损失
loss = loss_fn(predicts, y_data)
# 计算准确率
acc = paddle.metric.accuracy(predicts, y_data)
# 反向传播
loss.backward()
# 输出结果
if (batch_id+1) % 4 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(
epoch+1, batch_id+1, loss.numpy(), acc.numpy()))
# 更新参数
optim.step()
# 参数清零
optim.clear_grad()
模型验证#
test_loader = paddle.io.DataLoader(custom_dataset, batch_size=BATCH_SIZE, shuffle=True)
model.eval()
for batch_id, data in enumerate(test_loader()):
x_data = data[0] # 训练数据
y_data = data[1] # 标签
# 调用前向计算
predicts = model(x_data)
# 计算损失
loss = loss_fn(predicts, y_data)
# 计算准确率
acc = paddle.metric.accuracy(predicts, y_data)
# 模型验证没有反向传播,因此也就不会更新参数
# 输出结果
if (batch_id+1) % 4 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(
epoch+1, batch_id+1, loss.numpy(), acc.numpy()))
模型测试#
for batch_id, data in enumerate(test_loader()):
x_data = data[0] # 训练数据
predicts = model(x_data) # 调用前向计算
print("result: {}".format(predicts.numpy()))